| Pré. | Proc. |
Analyseur de codes
L'analyseur de code est un outil essentiel pour tous ceux qui traitent quotidiennement du code source.
Il peut effectuer des requêtes très complexes sur les référentiels de code source à une vitesse fulgurante, soit localement, soit sur un service cloud Sparx Intel. Les requêtes sont composées à l'aide d'un langage de haut niveau développé par Sparx System. Le langage utilise un vocabulaire restreint mais expressif qui est facile à apprendre et permet d'interroger les métriques de code beaucoup plus rapidement que les méthodes conventionnelles.
Accéder
|
Ruban |
Développer > Code source > Analyseur de code |
Menu de l'analyseur de code
Le menu de l'analyseur de code s'affiche lorsque vous cliquez sur l'icône ![]() dans le coin supérieur gauche de la fenêtre.
dans le coin supérieur gauche de la fenêtre.
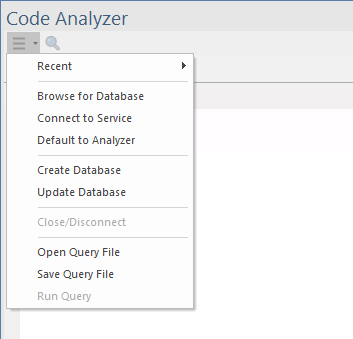
Le menu fournit diverses commandes pour les activités associées à l'utilisation de l'analyseur de code, notamment le choix d'une base de données Code Miner à utiliser, la mise à jour de la base de données Code Miner et l'ouverture d'un fichier de Query pour modification.
Ce tableau décrit chacune des commandes de menu.
Commande |
Description |
|---|---|
|
Récent |
Affiche un sous-menu qui fournit une liste des connexions récentes aux services et aux fichiers de base de données locaux . |
|
Parcourir la base de données |
Affiche une boîte de dialogue "sélecteur de fichiers", vous permettant de rechercher une base de données Code Miner sur votre machine. |
|
Se connecter au service |
Affiche la boîte de dialogue « Connexion à la base de données Code Miner », dans laquelle vous spécifiez les détails de connexion pour une (liste de) services de base de données Code Miner . |
|
Analyseur par défaut |
La sélection de cette option entraîne la connexion automatique de l'analyseur de code au service Code Miner configuré pour le Analyseur d'Exécution actif, au démarrage de l'analyseur de code. |
|
Créer une base de données |
Affiche la boîte de dialogue "Créer une base de données Code Miner ", qui vous permet de créer une base de données Code Miner à partir d'un référentiel de code source dans le système de fichiers. |
|
Mettre à jour la base de données |
Affiche la boîte de dialogue "Mise à jour de la base de données Code Miner ", qui vous permet d'effectuer une mise à jour incrémentielle d'une base de données Code Miner existante, afin d'incorporer les modifications récentes apportées aux fichiers de code source. |
|
Fermer/Déconnecter |
Ferme ou déconnecte de la bibliothèque ou du service Code Miner Database. |
|
Ouvrir le fichier de Query |
Affiche une boîte de dialogue "ouverture de fichier" vous permettant de choisir un fichier de requête mFQL dans le système de fichiers. |
|
Enregistrer le fichier Query |
Affiche une boîte de dialogue de « sauvegarde de fichier » vous permettant de sauvegarder la requête mFQL actuelle dans un fichier nommé . |
|
Query Exécuter |
Exécute la requête entière ou le contenu sélectionné de la requête saisie dans l'éditeur de l'onglet ' Query '. Raccourci . |
Avant d'utiliser l'analyseur
Avant de pouvoir utiliser l'analyseur de code, vous devez d'abord créer une base de données Code Miner ou en localiser une existante à laquelle l'analyseur de code peut accéder. La création d'une base de données Code Miner est résumée ici, ou vous pouvez lire une description détaillée dans la rubrique d'aide Création d'une nouvelle base de données Code Miner .
Selon l'emplacement de la bibliothèque que vous utiliserez, vous devez soit :
- Sélectionnez un fichier de bibliothèque Code Miner à utiliser, ou
- Connectez-vous à un service qui héberge une base de données Code Miner .
Création d'une base de données Code Miner
Les bases de données Code Miner sont construites à partir de référentiels de code source. Le processus est similaire à la compilation de code, utilisant la grammaire du langage pour analyser des fichiers individuels.
Il existe deux types de construction - complète et incrémentielle. La version complète initiale peut prendre un certain temps, mais les versions incrémentielles suivantes sont incroyablement rapides.
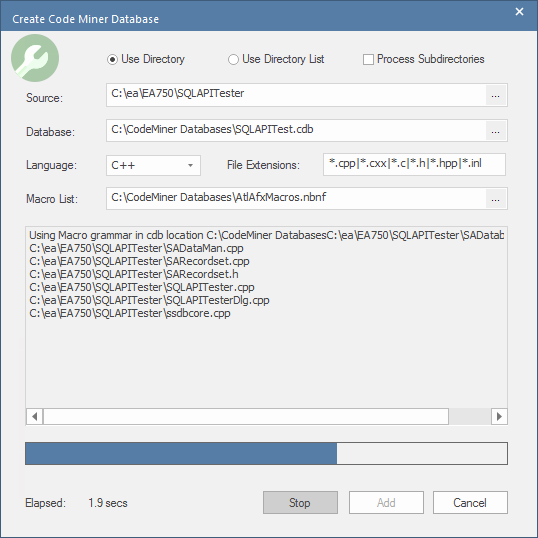
Utilisation d'un répertoire comme entrée
Vous pouvez sélectionner un seul dossier comme racine du code source que vous souhaitez compiler. Avec cette option, vous pouvez choisir d'inclure des sous-répertoires
Utilisation d'une liste de répertoires
Parfois, vous souhaitez utiliser plusieurs projets, mais tous les projets ne se trouvent pas dans un seul répertoire. Dans ce cas, vous pouvez créer un fichier texte qui répertorie le chemin d'accès complet à chaque dossier que vous souhaitez inclure et vous spécifiez ce fichier texte dans le champ "Source". Chaque chemin de répertoire doit être répertorié sur une ligne distincte.
c:\myprojects\project1\tools\scintilla
c:\mesprojets\projet2\src
d:\mylibs\lib1\src
Si vous souhaitez traiter de manière récursive les sous-répertoires d'un répertoire, faites précéder le chemin d'un point d'exclamation comme ceci :
!d:\mylibs\lib1\src
Toute ligne commençant par un caractère # est traitée comme un commentaire.
# inclure la scintille
c:\myprojects\project1\tools\scintilla
Langue
Dans ce champ, vous spécifiez le langage utilisé dans le code source à partir duquel cette base de données Code Miner est construite.
Les langages disponibles sont : C++, C# , Java, XML, MDGTechnology et Custom.
Liste des macros
Lorsque le langage sélectionné est 'C++', le champ de sélection 'Liste des macros' s'affiche. Pour C++, le succès et la profondeur des informations compilées dans la base de données peuvent être inextricablement liés à l'utilisation de macros. Ce champ peut être utilisé pour sélectionner un fichier macro nBNF qui sera utilisé comme composant de grammaire auxiliaire pour la compilation.
Par défaut, le fichier de macro sera par défaut le fichier de macro dans le dossier d'installation Enterprise Architect . Vous êtes libre de modifier ou d'étendre le contenu de ce fichier selon vos besoins - par exemple, lorsque vous avez besoin de corriger des erreurs signalées dans le fichier log de compilation.
Grammaire
Sparx Systems a développé des grammaires pour toutes les langues répertoriées dans la liste de sélection déroulante ; C++, C# , Java, XML et aussi MDGTechnology. Pour ces langues, un fichier de grammaire intégré est utilisé.
Il existe également une option pour sélectionner une langue « personnalisée ». Lorsque 'Personnalisé' est sélectionné, le champ 'Grammaire' s'affiche. Ce champ est utilisé pour spécifier un fichier contenant la grammaire de votre langue personnalisée. Le Code Miner utilisera ensuite cette grammaire pour analyser le code source écrit dans cette langue.
Les utilisateurs qui développent une langue personnalisée devront spécifier des règles de grammaire pour cette langue et les enregistrer dans un fichier nBNF. L'éditeur de grammaire d' Enterprise Architect est conçu spécifiquement à cette fin.
Le Help Topic Grammar Framework fournit des informations détaillées sur l'écriture d'une grammaire nBNF.
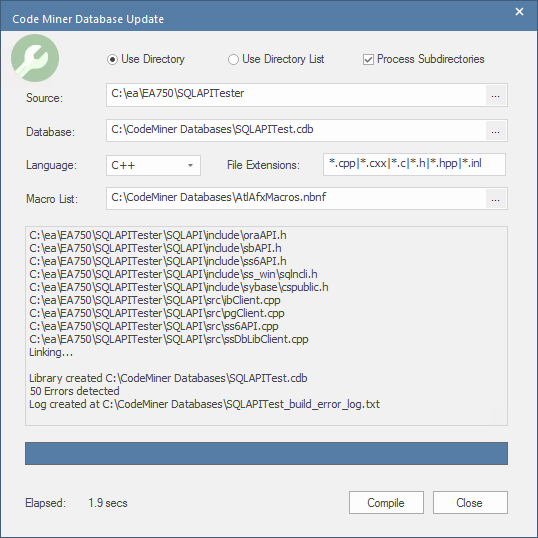
Mettre à jour une base de données Code Miner
De temps en temps, vous souhaiterez mettre à jour votre base de données Code Miner . Généralement, lorsque vous avez apporté des modifications à votre code source, mais également après la mise à jour d'un fichier de grammaire ou l'extension d'un fichier de macro.
Le processus de mise à jour d'une base de données est très similaire à la création d'une nouvelle base de données, mais plus rapide car vous ne partez pas de zéro. Choisissez simplement l'option de menu 'Mettre à jour la base de données'. La boîte de dialogue « Mise à jour de la base de données Code Miner » s'affiche. Les champs d'entrée seront remplis avec les valeurs de la dernière génération. Procédez comme pour 'Créer une base de données Code Miner '.
Sélection d'un fichier de base de données Code Miner
Si vous choisissez d'utiliser un fichier de bibliothèque pour votre base de données Code Miner , choisissez l'option de menu "Rechercher la base de données". Cela affichera un "Sélecteur de fichiers", où vous pourrez rechercher et sélectionner un fichier *.cdb.
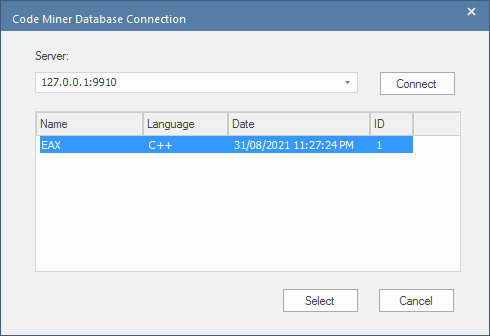
Connexion à un service
Lors de la connexion à un service, le dialogue liste toutes les bases de données hébergées par le service.
Vous pouvez choisir de sélectionner une base de données individuelle dans la liste, ou simplement cliquer sur le bouton Sélectionner, auquel cas les requêtes seront exécutées sur toutes les bases de données répertoriées par le service.
Exécution de requêtes
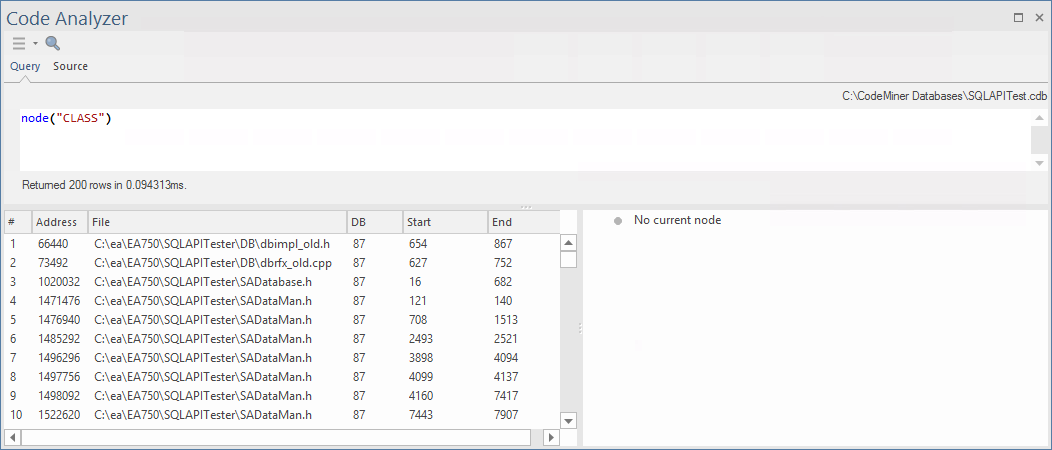
Une fois que vous êtes connecté à une base de données Code Miner , vous êtes prêt à commencer à exécuter des requêtes.
Pour exécuter une requête, sélectionnez l'onglet Query dans la fenêtre de l'analyseur de code, saisissez votre requête, puis cliquez sur l' ![]() pour exécuter la requête.
pour exécuter la requête.
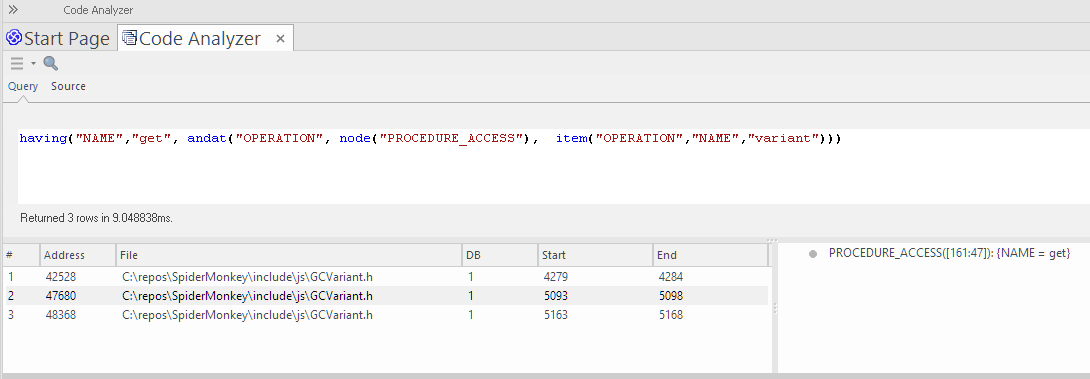
Dans cet exemple, nous avons exécuter un nœud de requête simple ( "CLASS" ), qui renverra tous les nœuds 'Class' trouvés dans la base de données Code Miner .
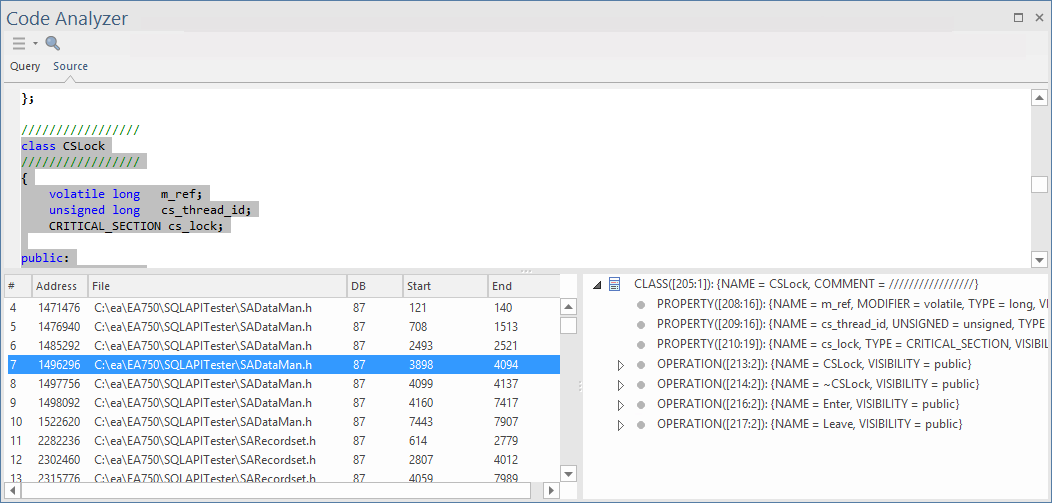
En sélectionnant un résultat dans le panneau en bas à gauche, l'onglet 'Source' est activé et affiche le code source correspondant au nœud sélectionné. Les détails de ce nœud de classe sont affichés dans le panneau inférieur droit.
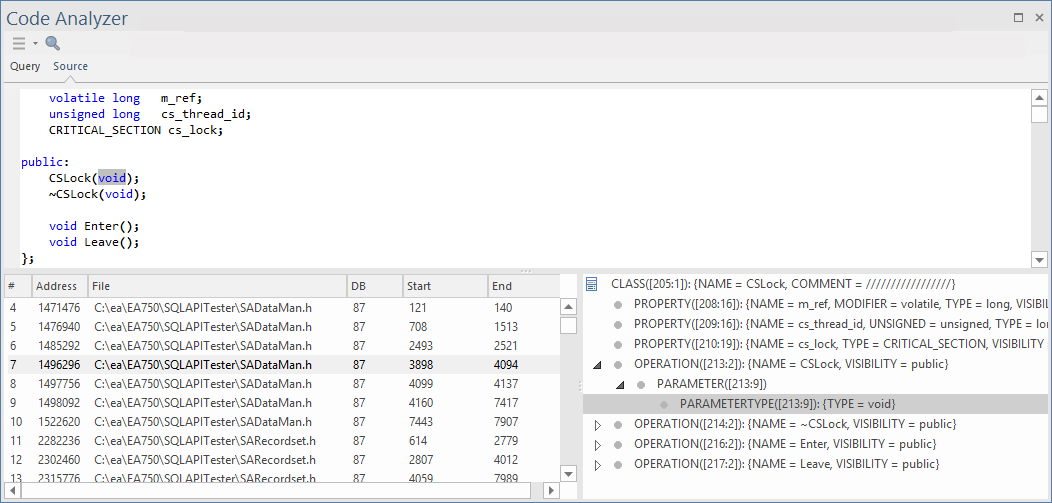
La sélection d'un élément de détail dans le panneau inférieur droit entraîne une réduction de la sélection dans le code source, comme illustré ici.
Query Example - Intersection
As an example, this mFQL query finds all the classes that have an operation named GetOption.andat( "CLASS", item("OPERATION", "NAME", "GetOption"), node("CLASS"))
This clause returns a set of operations for which the 'NAME' value is "GetOption":
item("OPERATION", "NAME", "GetOption")
This clause returns a set of all Class nodes:
node("CLASS")
Formal syntax:
andat( string:rule, set:left, set:right)
'andat' takes the set of operations (left), applies the rule "CLASS" (only include rows that have a CLASS parent), then intersects that set with the set of all known classes (right). If the intersection succeeds, the operation node is added to the result set, otherwise it is excluded.
Le langage de Query - mFQL
Le langage de requête utilisé avec l'analyseur de code est décrit en détail dans la rubrique d'aide Code Miner Query Language (mFQL) .
Une brève description et quelques exemples sont également présentés ici.
Le langage mFQL est basé sur des ensembles. Chaque instruction fonctionne en utilisant les différents types d'opérations sur les ensembles dont il n'y a que quelques-uns.
Apprendre encore plus
- Cadre Code Miner
- Bibliothèques Code Miner
- Code Miner Queries
- Code Miner Query Language (mFQL)
- Service Intel Sparx
- Scripts d’Analyseur - Analyseur d'Exécution
- Script Code Miner - Analyseur d'Exécution