| Pré. | Proc. |
Création d'une nouvelle base de données Code Miner
L'analyseur de code d' Enterprise Architect , les fonctionnalités Intelli-sense de ses éditeurs de code et ses outils de recherche utilisent tous les bases de données Code Miner .
Une base de données Code Miner est créée en analysant les fichiers de code source selon les règles de grammaire de la langue sélectionnée et en stockant l'arbre de syntaxe abstraite résultant, dans une base de données optimisée en lecture. Une ou plusieurs bases de données peuvent être combinées pour former une Bibliothèque Code Miner .
Accéder
|
Fenêtre de l'analyseur de code |
Dans la fenêtre de l'analyseur de code, cliquez sur le bouton de menu, |
|
Exécution Éditeur de Script Analyseur |
La fenêtre Éditeur de Script l' Analyseur d'Exécution ouverte, sélectionnez la page ' Code Miner > Bibliothèques', puis cliquez sur le bouton 'Créer'. |
Boîte de Dialogue Créer une base de données Code Miner
La boîte de dialogue "Créer une base de données Code Miner " est utilisée pour lancer le processus d'analyse des fichiers de code source afin de créer une base de données Code Miner . Dans le dialogue de fichier, vous spécifiez une plage d'entrées utilisées par le processus, telles que le dossier de code source, le fichier de langue et de liste de macros, ainsi que le nom du fichier de sortie. Les champs de dialogue sont décrits dans le tableau présenté ci-dessous.
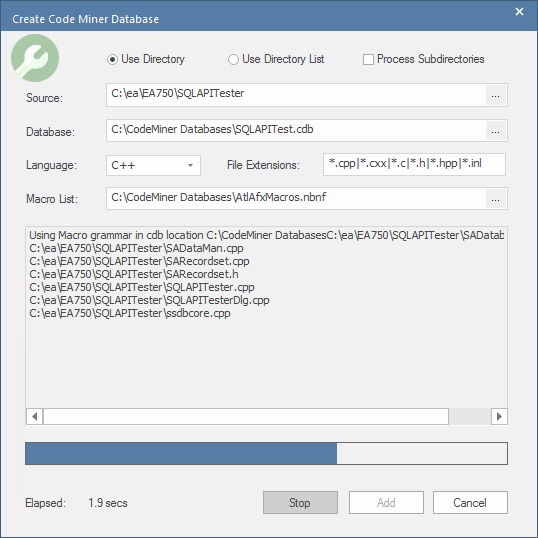
Champ |
La description |
Voir également |
|---|---|---|
|
Utiliser le répertoire |
Sélectionnez cette option lorsque tous les fichiers source à traiter résident dans un répertoire. Lorsque cette option est sélectionnée, la case à cocher "Traiter les sous-répertoires" est activée. |
|
|
Utiliser la liste des répertoires |
Sélectionnez cette option lorsque le code source de votre projet réside dans plusieurs répertoires distincts. Dans ce cas, vous utilisez le champ 'Source' pour spécifier un fichier qui contient une liste de répertoires contenant le code source à traiter. |
|
|
Traiter les sous-répertoires |
Cette case à cocher est activée lorsque l'option 'Utiliser le répertoire' est sélectionnée. Lorsqu'il est sélectionné, le fichier de code source résidant dans n'importe quel sous-répertoire du répertoire 'Source' spécifié sera également traité. |
|
|
La source |
Ce champ permet de spécifier le répertoire (ou les répertoires) contenant les fichiers de code source qui seront traités pour créer la base de données Code Miner . Lorsque l'option 'Utiliser le répertoire' est sélectionnée, ce champ est utilisé pour spécifier le dossier racine dans lequel rechercher les fichiers de code source. Lorsque l'option "Utiliser la liste de répertoires" est sélectionnée, ce champ est utilisé pour spécifier un fichier créé par l'utilisateur contenant une liste de noms de chemin vers les répertoires contenant les fichiers source à traiter. Cliquer sur le bouton |
|
|
Base de données |
Ce champ spécifie le chemin d'accès complet du fichier de base de données Code Miner qui sera créé. L'extension de nom de fichier '.cdb' est utilisée pour ce fichier. |
|
|
Langue |
Il s'agit d'une liste déroulante dans laquelle vous spécifiez la langue utilisée dans les fichiers de code source en cours de traitement. Il existe un certain nombre de langages pour lesquels Enterprise Architect fournit un support "intégré". (Il existe des grammaires intégrées utilisées pour analyser les langues prises en charge). Il existe également une option pour choisir une langue « personnalisée ». Si vous choisissez d'utiliser une langue personnalisée, vous devrez créer votre propre grammaire pour prendre en support l'analyse de cette langue. Lorsque l'option 'Personnalisé' est sélectionnée, le champ 'Fichier de grammaire' s'affiche, vous permettant de spécifier le fichier qui définit votre grammaire personnalisée. |
|
|
Extensions de fichiers |
Ce champ répertorie un certain nombre d'extensions de nom de fichier qui sont généralement associées aux fichiers de code source de la langue choisie. Seuls les fichiers dont les extensions de nom de fichier correspondent à celles de la liste seront traités par l'analyseur. Vous pouvez ajouter ou supprimer des extensions de nom de fichier selon vos besoins. |
|
|
Liste des macros |
Lorsque le langage sélectionné est 'C++', le champ de sélection 'Macro List' s'affiche. Le champ Liste de macros vous permet de spécifier un fichier qui fournit une liste de macros que l'analyseur doit ignorer lorsqu'il les rencontre. Pour le langage C++, les macros posent un problème à l'analyseur car elles masquent les constructions du langage natif. L'ajout du nom d'une macro au fichier de liste de macros et la mise à jour de la base de données effacent généralement toutes les erreurs liées à cette macro. Pour plus d'informations, consultez la section Extension du fichier de liste de macros ci-dessous. |
|
|
Fichier de grammaire |
Sparx Systems a développé des grammaires pour toutes les langues répertoriées dans la liste de sélection déroulante. C++, C# , Java, XML et aussi MDGTechnology. Il existe également une option pour sélectionner une langue "personnalisée". Les utilisateurs qui développent un langage personnalisé devront spécifier des règles de grammaire pour ce langage et les enregistrer dans un fichier nBNF, afin que Code Miner puisse analyser correctement le code source écrit dans ce langage. L'éditeur de grammaire d' Enterprise Architect est conçu spécifiquement à cette fin. Lorsque vous sélectionnez "Personnalisé" comme langue, vous devez alors spécifier le fichier de grammaire que vous avez créé pour cette langue, afin que le Code Miner puisse analyser correctement votre code source. Le Help Topic Grammar Framework fournit des informations détaillées sur l'écriture d'une grammaire nBNF. |
Cadre de grammaire |
|
Fenêtre de sortie |
La fenêtre de sortie affiche la progression de l'analyse des fichiers de code source. Une fois terminé, il affiche également les noms du fichier de base de données et du fichier log qui ont été créés ainsi que le nombre d'erreurs rencontrées. |
|
|
Bouton Compiler/Arrêter |
Le bouton 'Compiler' permet de lancer le traitement. Ce bouton se transforme en bouton 'Stop' une fois que le traitement commence, permettant à l'utilisateur d'abandonner l'opération. |
|
|
Ajouter un bouton |
Une fois qu'une base de données a été compilée, le bouton 'Ajouter' peut être utilisé pour ajouter cette base de données à une Bibliothèque Code Miner . Plusieurs bases de données peuvent être ajoutées pour créer une bibliothèque qui couvre de nombreux projets de code source. Note : Lorsque la boîte de dialogue 'Créer une base de données Code Miner ' est ouverte depuis la fenêtre de l'analyseur de code, le bouton 'Ajouter' n'est pas affiché. |
 ouvre une boîte de dialogue « Sélecteur de fichiers », qui vous permet de rechercher et de choisir un fichier avec l'extension « .ssdirlist ». Pour plus d'informations, consultez la section Fichier de liste de répertoires ci-dessous.
ouvre une boîte de dialogue « Sélecteur de fichiers », qui vous permet de rechercher et de choisir un fichier avec l'extension « .ssdirlist ». Pour plus d'informations, consultez la section Fichier de liste de répertoires ci-dessous.Fichier de liste de répertoires
Si vous choisissez de spécifier un fichier de liste de répertoires, vous devrez créer un simple fichier texte en utilisant l'extension de nom de fichier ".ssdirlist", qui répertorie le chemin complet vers chaque répertoire que vous souhaitez traiter, avec un chemin par ligne. Par exemple:
c:\myprojects\project1\tools\scintilla
c:\mesprojets\projet2\src
d:\mylibs\lib1\src
Si vous souhaitez traiter de manière récursive les sous-répertoires d'un répertoire répertorié, faites précéder ce chemin d'un point d'exclamation comme ceci :
!d:\mylibs\lib1\src
Toute ligne commençant par un caractère # est traitée comme un commentaire :
# inclure la scintille
c:\myprojects\project1\tools\scintilla
Extension du fichier de liste de macros
Pour le langage C++, les macros présentent un problème pour les grammaires car elles masquent les constructions du langage natif. L'analyseur ne peut pas effectuer de substitution sur les macros car elles sont souvent définies de manière conditionnelle et l'analyseur n'a aucune idée de l'architecture. Le fichier Macro List fournit une liste de macros que l'analyseur doit ignorer lorsqu'il les rencontre.
Lorsque vous créez une base de données Code Miner pour un référentiel de code source C++, des erreurs peuvent s'afficher. Lorsqu'une erreur se produit, utilisez le log des erreurs pour rechercher et inspecter la ligne de code à l'origine de l'erreur. Cela identifie presque toujours une macro à l'origine de l'échec de la grammaire. L'ajout de ce nom à la liste des macros et la mise à jour de la base de données effaceront généralement toutes les erreurs liées à cette macro.
Par exemple, le log des erreurs affiche cette erreur :
C:\ea\EA750\SQLAPITester\SQLAPI\include\asa\sqlfuncs.h, line:12, col:18, Symbole inattendu ','.
Après inspection, la ligne de code à l'origine de l'erreur est la suivante :
FUNC_INFO( externe , vide , _esqlentry_, sqlstop, (SQLCA *))
(Il existe également de nombreuses autres lignes similaires utilisant la macro 'FUNC_INFO'.)
Donc, nous éditons le fichier de liste de macros par défaut, 'AtxAflMacros.nbnf', en ajoutant cette ligne :
"FUNC_INFO" " ( " skipBalanced( " ( " , " ) " ) " ) " |
Cette ligne indique à l'analyseur, lorsqu'il rencontre la macro "FUNC_INFO" , d'appliquer la fonction skipBalanced( " ( " , " ) " ), qui prend deux paramètres ; dans ce cas, ce sont les parenthèses ouvrantes et fermantes. Ainsi, l'analyseur est chargé d'ignorer tout ce qui se trouve entre les parenthèses ouvrantes et fermantes.
Lorsque la modification apportée au fichier de la liste des macros est enregistrée et que la base de données est recompilée (mise à jour), toutes les erreurs relatives à la macro "FUNC_INFO" ont été éliminées.